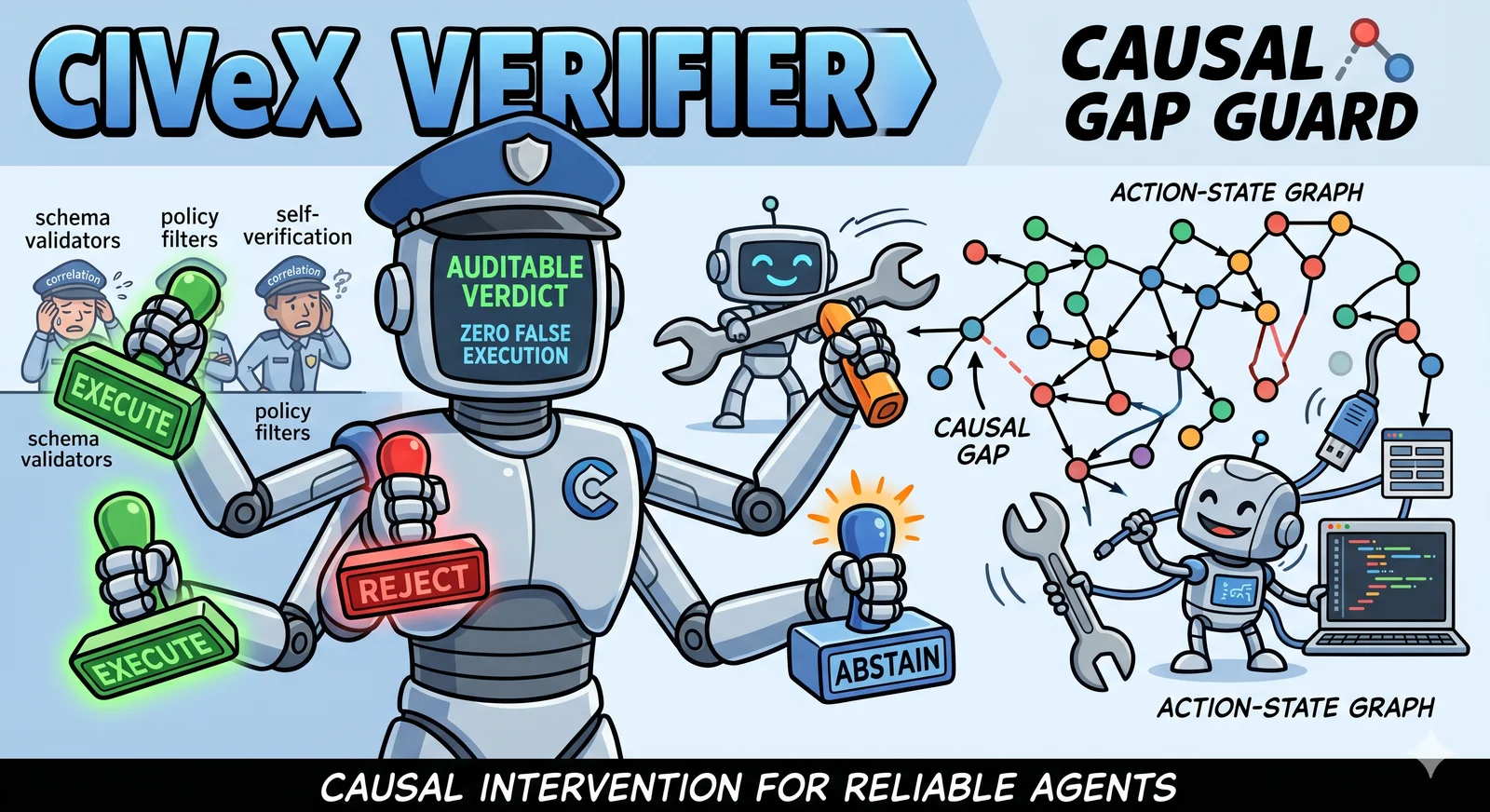
The Problem With Valid Tool Calls
Schema validators, policy filters, provenance checks, state predictors, and self-verification layers have become standard defenses for tool-using agents, but none of those safeguards address a more fundamental question: does a proposed action have an identifiable causal effect on the system state it is meant to change?
In confounded workflows, observational logs can make a particular action appear optimal when, in practice, executing it reduces utility. The action passes every syntactic and policy check, yet it fails on causal grounds. As the CIVeX research team notes, a valid tool call is not necessarily a valid intervention [1]. That gap between action validity and intervention validity is what existing safety stacks leave unaddressed.
What CIVeX Is
CIVeX is a causal intervention verifier designed to close that gap. The system takes a proposed action, maps it to a structural causal query over a committed action-state graph, and checks whether the causal effect of that action is identifiable given the graph structure and available data [1].
The verifier returns one of four auditable verdicts. EXECUTE signals that the causal effect is identified and the action clears all risk thresholds. REJECT signals that the effect is identifiable but the estimated outcome falls below acceptable bounds. EXPERIMENT signals that the effect cannot be identified from observational data alone and that a targeted experiment should be run to gather the needed evidence. ABSTAIN signals that neither identification nor safe experimentation is currently possible [1].
This four-verdict design gives operators a structured decision surface rather than a binary pass-or-fail gate, which is particularly relevant in production environments where the cost of inaction is not zero.
How the Verification Pipeline Works
Execution under CIVeX requires more than a passing verdict. The system demands a full causal certificate before allowing an action to proceed. That certificate must carry several components: a graph commitment specifying the assumed causal structure, an identification argument demonstrating that the target causal quantity can be estimated from available data, a one-sided lower confidence bound on the estimated effect, provenance records linking the estimate to its data sources, and explicit risk limits [1].
The requirement for a graph commitment is significant from an engineering standpoint. It forces the agent or the surrounding infrastructure to declare the assumed causal model explicitly, making that assumption auditable and version-controllable rather than implicit in a model’s weights or a policy filter’s logic. The lower confidence bound, rather than a point estimate, provides a conservative floor that accounts for sampling uncertainty before any irreversible action is taken.
Benchmark and Real-World Results
The research team evaluated CIVeX on Causal-ToolBench, a benchmark comprising 1,890 instances across seven random seeds, under both moderate and adversarial confounding conditions. Across all conditions, CIVeX produced zero observed false executions [1].
Under adversarial confounding, the verifier reached 84.9% accuracy and captured 81.1% of oracle utility, corresponding to a constrained utility score of +2.23 against the oracle’s +2.76. Notably, CIVeX was the only non-oracle method whose constrained utility under a zero-false-execution constraint exceeded the AlwaysAbstain floor, meaning it delivered positive value rather than simply refusing to act [1].
The team also tested CIVeX against two real-world production log datasets: IHDP and ZOZO Open Bandit, both of which use uniform-random ground truth to simulate deployment conditions. On those datasets, CIVeX matched oracle correct-execution rates within 0.1 percentage points and reduced per-execute false-execution rates by at least 50 times compared to naive baseline methods [1].
Where LLM-Based Verifiers Fit In
The research also benchmarked chain-of-thought LLM verifiers built on Anthropic Claude Opus and Claude Sonnet as an alternative approach to reducing false executions. Both models showed meaningful improvement over a terse baseline, cutting false-execution rates by roughly an order of magnitude [1].
However, under adversarial confounding conditions, Claude Opus’s utility fell to approximately 74% of CIVeX’s utility. The gap reflects a structural limitation: LLM-based verifiers reason about causal plausibility in natural language but do not perform formal identifiability checks against a committed causal graph. When confounding is deliberately adversarial, that informal reasoning degrades in ways that a graph-based identifiability check does not [1].
The comparison positions LLM verifiers as a meaningful improvement over unverified execution but not as a substitute for formal causal certification in high-stakes settings.
Implications for Agent Safety in Production
The zero-false-execution result across both benchmark and production log evaluations has direct implications for operators deploying tool-using agents in environments where incorrect actions carry meaningful costs, such as financial systems, healthcare workflows, or infrastructure automation.
The four-verdict system provides an audit trail that schema validators cannot produce. Each EXECUTE verdict is backed by a causal certificate with explicit graph commitments and provenance, giving compliance and operations teams a reviewable record of why an action was cleared [1]. The EXPERIMENT verdict is particularly useful in production contexts, as it gives agents a principled path forward when causal identification fails rather than forcing a binary choice between execution and abstention.
The researchers frame intervention identifiability, not action validity, as the missing primitive for reliable tool use [1]. That framing suggests that production agent stacks may need to incorporate causal graph management as a first-class infrastructure concern alongside existing schema and policy layers.
FAQ
Q. Does CIVeX require a pre-specified causal graph, and what happens if the graph is misspecified? CIVeX requires a committed action-state graph as part of the causal certificate before any EXECUTE verdict is issued [1]. The research does not detail automated graph discovery; operators must supply or maintain the graph. Misspecification would affect the identification argument and could cause the verifier to issue incorrect verdicts, which is a known limitation of any structural causal model approach.
Q. How does CIVeX perform when the correct action is to execute but the causal effect is unidentifiable? When identifiability cannot be established from observational data, CIVeX issues an EXPERIMENT or ABSTAIN verdict rather than EXECUTE [1]. This conservative posture is what drives the zero-false-execution result, but it also means some correct executions are deferred or blocked, which is reflected in the 81.1% oracle utility figure under adversarial confounding.
Q. Can CIVeX be integrated with existing agent frameworks that already use schema validators and policy filters? The paper positions CIVeX as a complementary layer rather than a replacement for existing safeguards [1]. The causal certificate requirement is a pre-execution gate that sits alongside, not instead of, schema and policy checks. Integration would require infrastructure for maintaining causal graphs and computing identification arguments, which are not standard components in current agent frameworks.
Q. How do the IHDP and ZOZO Open Bandit results translate to other production domains? Both datasets use uniform-random ground truth to approximate deployment conditions, and CIVeX matched oracle correct-execution within 0.1 percentage points on both [1]. The degree to which those results generalize depends on how closely a target domain’s confounding structure resembles the tested datasets; domains with more complex or dynamic confounding may see different performance characteristics.
Q. What is the computational overhead of running CIVeX’s identifiability checks at inference time? The published research does not report latency or computational cost figures for the verification pipeline [1]. Operators evaluating CIVeX for latency-sensitive production deployments would need to benchmark the identifiability checking and confidence bound computation steps against their own throughput requirements.
Key takeaways
- CIVeX addresses a gap that schema validators and policy filters cannot: whether a proposed action has an identifiable causal effect, not just a valid structure.
- The verifier issues one of four verdicts (EXECUTE, REJECT, EXPERIMENT, ABSTAIN), each backed by a causal certificate that includes graph commitments, an identification argument, a lower confidence bound, provenance, and risk limits.
- On Causal-ToolBench, CIVeX produced zero false executions under both moderate and adversarial confounding and was the only non-oracle method to exceed the AlwaysAbstain utility floor.
- On real production log datasets IHDP and ZOZO Open Bandit, CIVeX matched oracle correct-execution within 0.1 percentage points and reduced per-execute false-execution by at least 50 times over naive baselines.
- Chain-of-thought LLM verifiers using Anthropic Claude Opus and Sonnet reduce false executions significantly over terse baselines but fall to roughly 74% of CIVeX’s utility under adversarial confounding, indicating that informal causal reasoning does not substitute for formal identifiability checking.